I recently picked up the book Gender Inclusive Game Design: Expanding the Market by Sheri Graner Ray from the school library when looking for books to read whilst preparing my upcoming mini-course Computer Science and Games: Not Just For Boys! Despite some of the negative reviews on the Amazon website (which aren't without merit), there was information in this book that seemed to ring true to me as a female and potential gamer. What follows is a mixture of my own thoughts with some ideas suggested in the book.
One of the book's first discussions revolves around the issue of boys being better exposed to technology in their childhoods than girls are. When I was growing up, this was probably quite true. It was the boys who went to computer camps, not girls. It was the boys who were given games to play on the computer, while the girls received educational titles like typing tutors. And, of course, a lot of the game marketing through the 80's and early 90's targeted males (often featuring Graner Ray's favorite term: "hyper-sexualized women") .
All that changed in the mid-nineties with the introduction of Barbie Fashion Designer in 1996. Well... almost changed. While the incredible sales numbers for this product proved that girls would play computer games, the industry was not able to see past this one concept. When others failed to capitalize on mimics of the Barbie game, it was as though they gave up and went back to creating male-friendly titles. To this day, the female market, which is actually larger than the male market in numbers, is largely ignored.
But who cares, right? I mean, the video game industry is still growing in huge ways, so why worry about the girl gamers?
Well, for one thing, that growth is predicted to slow in the US this year. Perhaps the momentum could be maintained instead if sales to female gamers picked up the slack. Even if it doesn't slow, who wouldn't want to make more money by simply putting in a little extra effort to target a portion of titles to girls, or simply make all the titles a bit more female-friendly?
Obviously the task must require more than "a little extra effort" if few are successfully doing it yet. Still, innovations like those created for the Wii seem to be attracting whole new demographics including girls and even beyond into groups like the elderly, so what's the secret? There are a few things worth keeping in mind when trying to include a larger group of people in your target audience.
One key suggestion made by Ms. Graner Ray revolves around the notion of conflict and its resolution. I remember a male friend once commenting back in high school that he wished girls could resolve problems amongst themselves like the boys did -- by having a (possibly serious) fight after which everything would be ok -- rather than holding grudges and carrying on the conflict for a long time. It was then on that I truly realized how differently males and females handle conflict. Boys favor direct conflict situations and girls prefer indirect conflict. Unfortunately, many modern video games tend to cater towards the former.
To expand the appeal of a game to the other half of the market, designers can consider providing more than one option for resolving conflict in a game, or, if designed specifically for women, concentrate on indirect conflict on its own. In indirect conflict, the player is not specifically pitted against another character or player; that is, one player cannot specifically alter the outcome for the other. Gymnastics is an example of this because each competitor's success is independent of the others. This also shows why titles like Myst, with many puzzles and no face to face boss fighting, are more popular among females.
Another important piece of information brought up by the book is that males and females tend to respond to particular stimuli differently. It's probably not surprising that males respond physiologically to visual stimulus while females get that type of response from emotional stimuli. That's not to say that males can't be emotional and that females can't appreciate visual art (for example); rather, it simply means that a physiological reaction is not elicited.
Now, nobody is suggesting that every video game has to remind you of a sappy romance novel for women to be interested. Instead, introducing into story lines a meaningful goal that is socially significant can keep girls interested in the game. I can say for myself that this really does make a huge difference in my enjoyment of a game. I want to feel like I've accomplished something, and saving a village filled with characters I've come to really like (even love!) is the reward I am seeking for finishing the game. According to my husband Andrew, it's not like this end goal isn't appealing to guys as well, but it seems that males may be able to get more enjoyment out of games without this element than girls do. (Why? I'd imagine that the other aspects discussed here probably provide some clues.)
Another interesting aspect of girls and gaming is that, apparently, girls don't find numerical scores important. They also don't care for the kind of game where you can die for making a mistake, forcing you back to the beginning. Once again, I must say this is true for me. I can remember back in the 90's, when my brother and I had a Sega Genesis, I couldn't really play the games that forced you to restart from the beginning each time you died (which was pretty much all of them). Instead, I watched my brother, since he had better skills built up thanks to a lot of patience, and therefore quickly didn't die nearly as often as I would. Ever since then I was a backseat gamer. Only recently have I (almost) picked up games again, largely thanks to the Wii.
To address this aspect of gaming, titles that don't include win/lose scenarios can be produced. The Sims is a good example of this type of game and the alternative reward system (i.e. you don't really 'beat' the game). On top of this, the traditional game style could simply be augmented with alternate rewards, such as exploration and side quests (which could also help enhance the story's emotional tie-in!). Other simple additions like the ability to experiment, such as the ability to try your own terrain maps in certain areas, also seem to be a hit with female gamers. Finally, adjusting the response-to-error actions could help. Even just a little more forgiveness could go a long way while still keeping an element of challenge intact.
There are many more ideas for how to expand the audience of games in the book, but I'll let you to read up on it on your own if you are interested. In the meantime, I would be very interested to hear about your own experiences in relation to these concepts, whether you are male or female. How accurate do you think they are?

Friday, January 25, 2008
Monday, January 21, 2008
Augmented Reality and Games
Although my schedule this semester allows me to work from home on Fridays, I decided to head into school for what may have been the last presentation given by candidates of a gaming faculty position here at Carleton (two of the other talks were covered here and here). This talk was given by Mark Fiala, currently of the NRC, regarding his vision of the future of augmented reality gaming.
Dr. Fiala began his talk with this loaded question: "Is gaming a valid research area?" While it seems strange to suggest that it is, it does in fact have a lot of value in the academic world. For instance, it does a good job of motivating students to learn computer science in the first place. But beyond that, one must consider the research results beyond their application to gaming. Techniques developed for the purpose of games have benefits in other areas as well, including medical computing, computer aided drawing, robotics, artificial intelligence, and even military training. Or, if that's not enough to convince, then think of the application of games as just another way to validate the theory.
In The World According To Mark, gaming will move more toward console applications and away from the PC. Multi-player games will gain momentum, and players will expect full mobility (including being able to play outdoors). And, the big one, is that augmented reality will play a major part in the games of the future. This means that it is an exciting time to be a researcher in computer vision in general and AR in particular. If one is lucky, he can ride the wave to where the future is probably headed anyway.
So what is augmented reality, anyway? Although I wrote a bit about augmented reality here, here's a little reminder: a bit like virtual reality, augmented reality mixes real video with computer generated objects and information. This could be seen as a new kind of improvement to the human-computer interface.
Back to games. There are two main paradigms for AR games. First, the magic lens makes use of a portable device with a front facing camera. You see the real world as per usual on the screen with some computer generated goodies added on top. Second, the magic mirror reflects footage of you back at you as if looking in a mirror. You might have some specially recognized tags strategically positioned on your body that can be used to augment your image with just about anything. Some examples shown included putting a scuba suit on someone and turning another person into a robot.
The magic lens concept was used in the popular exhibit that traveled (is still traveling?) across the US in various science museums called "Star Wars: Where Science Meets Imagination." The photo below shows a user interacting with the game, including a view of the augmented portion.
 (Image from here)
(Image from here)
From the OMSI web site describing the exhibits:
To take things to the next level, imagine playing Halo in real life. All you would need is a series of rooms or hallways marked up with tags, and some kind of head mounted camera and display unit. You would be able to see where obstacles were, though not necessarily as they are in the real world. It would be like laser tag, but with animated violence!
The final step, at least for now, would be to bring it all outside into the world's playground. Here, of course, there are no tags, so natural features are required. Extra sensors would be required, like GPS and orientation. Some computer vision magic would help pinpoint the exact location of a player once the GPS gives a rough enough idea to retrieve local context information.
I'm happy to call gaming a research area with all these exciting opportunities related to augmented reality. I guess we'll have to wait and see who gets hired for this new games faculty position, but if someone into AR and computer vision ends up on board, I will certainly be watching their research, and maybe even working with them one day!
Dr. Fiala began his talk with this loaded question: "Is gaming a valid research area?" While it seems strange to suggest that it is, it does in fact have a lot of value in the academic world. For instance, it does a good job of motivating students to learn computer science in the first place. But beyond that, one must consider the research results beyond their application to gaming. Techniques developed for the purpose of games have benefits in other areas as well, including medical computing, computer aided drawing, robotics, artificial intelligence, and even military training. Or, if that's not enough to convince, then think of the application of games as just another way to validate the theory.
In The World According To Mark, gaming will move more toward console applications and away from the PC. Multi-player games will gain momentum, and players will expect full mobility (including being able to play outdoors). And, the big one, is that augmented reality will play a major part in the games of the future. This means that it is an exciting time to be a researcher in computer vision in general and AR in particular. If one is lucky, he can ride the wave to where the future is probably headed anyway.
So what is augmented reality, anyway? Although I wrote a bit about augmented reality here, here's a little reminder: a bit like virtual reality, augmented reality mixes real video with computer generated objects and information. This could be seen as a new kind of improvement to the human-computer interface.
Back to games. There are two main paradigms for AR games. First, the magic lens makes use of a portable device with a front facing camera. You see the real world as per usual on the screen with some computer generated goodies added on top. Second, the magic mirror reflects footage of you back at you as if looking in a mirror. You might have some specially recognized tags strategically positioned on your body that can be used to augment your image with just about anything. Some examples shown included putting a scuba suit on someone and turning another person into a robot.
The magic lens concept was used in the popular exhibit that traveled (is still traveling?) across the US in various science museums called "Star Wars: Where Science Meets Imagination." The photo below shows a user interacting with the game, including a view of the augmented portion.
(Image from here)From the OMSI web site describing the exhibits:
Building Communities and Augmented Reality. Visitors build a spaceport, moisture farm community and walled Jawa town. Placing cards on a table - the physical landscape - a computer superimposes a building on a site in virtual reality and real time.This magic lens paradigm has a lot of potential, particularly for tabletop games. Action and strategy titles could be shipped with a specialized mat with the appropriate tag marker system to base the augmentations off of. These tags can even be hidden into game art if some cleverness is applied. Perhaps one day even World of Warcraft will be played as a tabletop game in 3D!
To take things to the next level, imagine playing Halo in real life. All you would need is a series of rooms or hallways marked up with tags, and some kind of head mounted camera and display unit. You would be able to see where obstacles were, though not necessarily as they are in the real world. It would be like laser tag, but with animated violence!
The final step, at least for now, would be to bring it all outside into the world's playground. Here, of course, there are no tags, so natural features are required. Extra sensors would be required, like GPS and orientation. Some computer vision magic would help pinpoint the exact location of a player once the GPS gives a rough enough idea to retrieve local context information.
I'm happy to call gaming a research area with all these exciting opportunities related to augmented reality. I guess we'll have to wait and see who gets hired for this new games faculty position, but if someone into AR and computer vision ends up on board, I will certainly be watching their research, and maybe even working with them one day!
Saturday, January 19, 2008
Procedural Generation in Games
Ever wondered why, in games like Grand Theft Auto, you generally can't get into the buildings of cities to explore their interiors? Usually, it's a matter of time and memory, but these restrictions may change in the near future thanks to new techniques in procedural generation.
If a designer were forced to meticulously create the interiors of each and every building in an urban sandbox game like GTA, the game would no doubt end up well over budget. Even if the time were allotted, a typical game or DVD disc might not even have the capacity to hold all the models. So what if, instead, you could build up the models as they are required based on only a small, unique piece of information? That's what the second talk I saw for the candidates of a faculty position here at Carleton was all about (the first talk being on research in computational video). It was called "Generation P: The P Stands for Simulation" and given by Dr. Anthony Whitehead, who currently works in the School of Information Technology here at Carleton.
Procedural generation is all about creating objects and behaviors from some set of rules rather than explicit control from designers and developers. This makes the content available on demand, and not only reduces development time for a game, but can also add to the realism (since no two objects will be the same), unpredictability, and freedom of action on the part of the gamer.
There are some recent games that are out (or almost out) using procedural generation. In fact, the latest Grand Theft Auto (IV), which is allegedly going to be released sometime between February and April 2008, is said to use procedural generation to increase the number of explorable building interiors. The upcoming game Spore is almost completely procedural based, and many other simulation games like The Sims tend to use a lot of this technique. Other titles that made (or will make) use of procedural generation of some kind include Oblivion: The Elder Scrolls IV, kkreiger, Elite, and Diablo I and II.
You can almost think of procedural generation as a sneaky method for compression. After all, just one small seed value can be used to build the rest of an entire building, making use of the fact that a certain random number generation will always produce the same sequence of numbers. It is by using this fact that developers can ensure the same building is rebuilt every time it is needed.
However, there lies a small challenge still: if a building is destroyed and rebuilt several times during a gaming session, what happens to the changes that the gamer has made due to interactions within? The proven solution turns out to be as simple as you might imagine. A simple hash table is all that is required to persist the interactions.
You can learn more about procedural generation for buildings, with change persistence, in the paper Dr Whitehead co-authored: Lazy Generation of Building Interiors in Realtime.
It's not hard to imagine how procedurally generated content could be applied to many other aspects beyond graphical models. For instance, music in games could be algorithmically generated rather than composed, which could allow, for instance, easier mechanisms for transitioning between different areas on a map that require music of different moods. It will be interesting to see whether games continue along this path and what the results will be.
If a designer were forced to meticulously create the interiors of each and every building in an urban sandbox game like GTA, the game would no doubt end up well over budget. Even if the time were allotted, a typical game or DVD disc might not even have the capacity to hold all the models. So what if, instead, you could build up the models as they are required based on only a small, unique piece of information? That's what the second talk I saw for the candidates of a faculty position here at Carleton was all about (the first talk being on research in computational video). It was called "Generation P: The P Stands for Simulation" and given by Dr. Anthony Whitehead, who currently works in the School of Information Technology here at Carleton.
Procedural generation is all about creating objects and behaviors from some set of rules rather than explicit control from designers and developers. This makes the content available on demand, and not only reduces development time for a game, but can also add to the realism (since no two objects will be the same), unpredictability, and freedom of action on the part of the gamer.
There are some recent games that are out (or almost out) using procedural generation. In fact, the latest Grand Theft Auto (IV), which is allegedly going to be released sometime between February and April 2008, is said to use procedural generation to increase the number of explorable building interiors. The upcoming game Spore is almost completely procedural based, and many other simulation games like The Sims tend to use a lot of this technique. Other titles that made (or will make) use of procedural generation of some kind include Oblivion: The Elder Scrolls IV, kkreiger, Elite, and Diablo I and II.
You can almost think of procedural generation as a sneaky method for compression. After all, just one small seed value can be used to build the rest of an entire building, making use of the fact that a certain random number generation will always produce the same sequence of numbers. It is by using this fact that developers can ensure the same building is rebuilt every time it is needed.
However, there lies a small challenge still: if a building is destroyed and rebuilt several times during a gaming session, what happens to the changes that the gamer has made due to interactions within? The proven solution turns out to be as simple as you might imagine. A simple hash table is all that is required to persist the interactions.
You can learn more about procedural generation for buildings, with change persistence, in the paper Dr Whitehead co-authored: Lazy Generation of Building Interiors in Realtime.
It's not hard to imagine how procedurally generated content could be applied to many other aspects beyond graphical models. For instance, music in games could be algorithmically generated rather than composed, which could allow, for instance, easier mechanisms for transitioning between different areas on a map that require music of different moods. It will be interesting to see whether games continue along this path and what the results will be.
Thursday, January 17, 2008
VideoTrace
On a recent journey through the Internet I stumbled across a great little research project with a lot of commercial potential. You may have heard of it, too, given its media coverage thus far. The prototype is dubbed VideoTrace and lives up to its name: it allows a user to interactively trace objects found in video to create three-dimensional models of them.
Systems that use image data to guide user interactions when creating models already exist. However, the amount of time and effort required to get those inputs just right can make these systems cumbersome and inefficient. VideoTrace makes good progress in alleviating this problem by using computer vision techniques to obtain data that ultimately reduce the amount of user input needed.
Some techniques attempt to use images of the object to be modeled to automatically reconstruct the object's points in 3D. However, these methods tend to suffer from ambiguities in the image data itself, as well as problems with camera motion degeneracies and lack of distinct feature points found on the object's surface. In VideoTrace, a user instead sketches lines and curves over the object, allowing for an automatic reconstruction that interprets these 2D constructs and uses them in the 3D reconstruction process.
As you can see, VideoTrace melds the two worlds of user-guided and automatic reconstruction when creating a 3D model based on an object found in a video sequence. You shouldn't view it as a complete replacement for 3D modeling, but rather an assistant in the process.
Also a part of the processing stage, pixels will be clustered together into what are called "superpixels" based on their color. Now each subsequent operation will work on these cells of pixels rather than the individual entities.
Now the user is ready to begin tracing the object they want a model of. First, they might use lines. These lines don't have to be drawn so accurately that they fit the object down to the pixel, since the superpixels will be considered in the refinement of the lines drawn. Sets of lines that form polygons will become one of the 3D object's faces.
As the user is drawing, they can flip to another frame of video and continue working there. The model computed so far from the first frame will be reprojected into the new frame. This means that even if the camera is looking at the object from a different viewpoint, the model drawn will still fit fairly well around it.
This is possible because the system is working in the background to compute the 3D shape and position of the model, continuously re-estimating the results based on new lines and curves drawn by the user.
Speaking of curves, the type of curves that can be drawn are called Nonuniform Rational B-Splines, or NURBS. The idea is that these 2D constructs can be drawn within the 3D space of the objects in the video. The estimation of the curves is both fast enough to be real-time for interactivity, and flexible enough to handle ambiguity. These curves can be constrained into a plane if necessary, as well.
From these curves, the user can create extrusions. The curves are dragged, and the vector representing the direction of movement is the normal of the plane the curve lies in. With multiple curves, surfaces can be generated in the final reconstruction, where the object points that are available from the preprocessing stage can be used to help fit the surfaces correctly to the actual object.
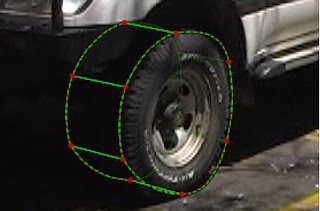 (Image from SIGGRAPH article)
(Image from SIGGRAPH article)
Finally, because not all objects are visible on the screen at one time, the user can be limited in what they are able to trace. Luckily, there is a mechanism that helps alleviate that problem: the user can copy and mirror a set of surfaces about a particular plane.
Nonetheless, when you have a look at the videos (larger or smaller) of VideoTrace in action, I think you will agree how impressive the results can be. There is no doubt that the video game and animation industries should be very interested in such a package to help speed up their modeling pipelines.
Systems that use image data to guide user interactions when creating models already exist. However, the amount of time and effort required to get those inputs just right can make these systems cumbersome and inefficient. VideoTrace makes good progress in alleviating this problem by using computer vision techniques to obtain data that ultimately reduce the amount of user input needed.
Some techniques attempt to use images of the object to be modeled to automatically reconstruct the object's points in 3D. However, these methods tend to suffer from ambiguities in the image data itself, as well as problems with camera motion degeneracies and lack of distinct feature points found on the object's surface. In VideoTrace, a user instead sketches lines and curves over the object, allowing for an automatic reconstruction that interprets these 2D constructs and uses them in the 3D reconstruction process.
As you can see, VideoTrace melds the two worlds of user-guided and automatic reconstruction when creating a 3D model based on an object found in a video sequence. You shouldn't view it as a complete replacement for 3D modeling, but rather an assistant in the process.
How Does It Work?
A preprocessing stage must be completed before the user even looks at the video sequence. At this point, structure and motion analysis is performed. This means that a sparse set of 3D points are estimated, as well as parameters describing the camera that took the video, including such parameters as focal length. The freely available Voodoo Camera Tracker is used to calculate this. The 3D points computed will give three-dimensional context and meaning to the lines and curves that the user will draw in 2D.Also a part of the processing stage, pixels will be clustered together into what are called "superpixels" based on their color. Now each subsequent operation will work on these cells of pixels rather than the individual entities.
Now the user is ready to begin tracing the object they want a model of. First, they might use lines. These lines don't have to be drawn so accurately that they fit the object down to the pixel, since the superpixels will be considered in the refinement of the lines drawn. Sets of lines that form polygons will become one of the 3D object's faces.

As the user is drawing, they can flip to another frame of video and continue working there. The model computed so far from the first frame will be reprojected into the new frame. This means that even if the camera is looking at the object from a different viewpoint, the model drawn will still fit fairly well around it.
This is possible because the system is working in the background to compute the 3D shape and position of the model, continuously re-estimating the results based on new lines and curves drawn by the user.
Speaking of curves, the type of curves that can be drawn are called Nonuniform Rational B-Splines, or NURBS. The idea is that these 2D constructs can be drawn within the 3D space of the objects in the video. The estimation of the curves is both fast enough to be real-time for interactivity, and flexible enough to handle ambiguity. These curves can be constrained into a plane if necessary, as well.
From these curves, the user can create extrusions. The curves are dragged, and the vector representing the direction of movement is the normal of the plane the curve lies in. With multiple curves, surfaces can be generated in the final reconstruction, where the object points that are available from the preprocessing stage can be used to help fit the surfaces correctly to the actual object.
 (Image from SIGGRAPH article)
(Image from SIGGRAPH article)Finally, because not all objects are visible on the screen at one time, the user can be limited in what they are able to trace. Luckily, there is a mechanism that helps alleviate that problem: the user can copy and mirror a set of surfaces about a particular plane.
Conclusion
As mentioned before, VideoTrace is not intentioned to replace other modeling software. Some problems may occur using it that need to be touched up later on. For example, because each surface is estimated individually, the global properties of the structure (regularity and symmetry for instance) may not be captured.Nonetheless, when you have a look at the videos (larger or smaller) of VideoTrace in action, I think you will agree how impressive the results can be. There is no doubt that the video game and animation industries should be very interested in such a package to help speed up their modeling pipelines.
Monday, January 14, 2008
Research in Computational Video
From what I understand, the seminar given to the School of Computer Science last week by Gerhard Roth (entitled Past, Current and Future Research in Computational Video with Applications to Gaming) was part of a competition for a faculty position required for the new game development program. I believe the idea was to have candidates share the kind of research they do and how it would be useful to game development. Dr. Roth was the first to present and he discussed his involvement in some really interesting computer vision research over the past decade or so.
Dr. Roth was part of the computational video group at the NRC (National Research Council Canada) before its funding was cut, and he teaches a computer vision course to fourth year computer science students here at Carleton (which I took during my undergrad).
One of the research projects Dr. Roth was involved with is the NAVIRE project. Very similar in nature to Google Street View, this project was a collaborative effort between the University of Ottawa and the NRC. The team used panoramic cameras to capture surroundings from the viewpoint of a person traveling along a road. The captured data was transformed into cubes, which could then be viewed with specialized software. Dr. Roth claims that NAVIRE solved several problems that Google's system did not, though it is not immediately clear to me what these are. Sifting through some of their publications might shed some light on this.
Another interesting project described in Dr. Roth's presentation related to another technology that should interest Google: image classification and retrieval. For the former, the user would select a subimage, probably a particular object to search for, and the system would retrieve all images that contained a subimage strongly similar to the search criteria image. To do this, various lighting conditions have to be accounted for as well as slightly different perspective viewpoints or scales. Occlusions must also be considered. For the latter, a number of images are categorized into a predefined set of semantic descriptions, such as car, dog, umbrella, and so on. After these categories are trained using a control set of images, the system would be able to give the probability that a new image belongs to a particular category. Test results are decent with only 100 training images for each category.
There were more projects mentioned in the presentation, but I'd like to move to those that interest me the most. I've discussed the concept of tangible user interfaces more than once (here and here), so by now it should be obvious how excited the topic makes me. Watching Dr. Roth talk about his experiences with them (under the mostly equivalent name of perceptual user interfaces) reminded me of this, and even gave me a whole new idea for a thesis! (I'll save a post on this new idea for another day, maybe after I talk to my supervisor about it).
In particular, Dr. Roth has been involved a lot with something called augmented reality. This should not be confused with virtual reality: the former uses real live video feeds and adds interesting computed imagery to it, while virtual reality tends not to combine real video with the virtual. The image below shows a good example of how augmented reality could be used.
 (Image from http://www.vr.ucl.ac.uk/projects/arthur/)
(Image from http://www.vr.ucl.ac.uk/projects/arthur/)
Dr. Roth was part of the computational video group at the NRC (National Research Council Canada) before its funding was cut, and he teaches a computer vision course to fourth year computer science students here at Carleton (which I took during my undergrad).
One of the research projects Dr. Roth was involved with is the NAVIRE project. Very similar in nature to Google Street View, this project was a collaborative effort between the University of Ottawa and the NRC. The team used panoramic cameras to capture surroundings from the viewpoint of a person traveling along a road. The captured data was transformed into cubes, which could then be viewed with specialized software. Dr. Roth claims that NAVIRE solved several problems that Google's system did not, though it is not immediately clear to me what these are. Sifting through some of their publications might shed some light on this.
Another interesting project described in Dr. Roth's presentation related to another technology that should interest Google: image classification and retrieval. For the former, the user would select a subimage, probably a particular object to search for, and the system would retrieve all images that contained a subimage strongly similar to the search criteria image. To do this, various lighting conditions have to be accounted for as well as slightly different perspective viewpoints or scales. Occlusions must also be considered. For the latter, a number of images are categorized into a predefined set of semantic descriptions, such as car, dog, umbrella, and so on. After these categories are trained using a control set of images, the system would be able to give the probability that a new image belongs to a particular category. Test results are decent with only 100 training images for each category.
There were more projects mentioned in the presentation, but I'd like to move to those that interest me the most. I've discussed the concept of tangible user interfaces more than once (here and here), so by now it should be obvious how excited the topic makes me. Watching Dr. Roth talk about his experiences with them (under the mostly equivalent name of perceptual user interfaces) reminded me of this, and even gave me a whole new idea for a thesis! (I'll save a post on this new idea for another day, maybe after I talk to my supervisor about it).
In particular, Dr. Roth has been involved a lot with something called augmented reality. This should not be confused with virtual reality: the former uses real live video feeds and adds interesting computed imagery to it, while virtual reality tends not to combine real video with the virtual. The image below shows a good example of how augmented reality could be used.
(Image from http://www.vr.ucl.ac.uk/projects/arthur/)Here, the two users have headsets on that show them a video feed of whatever is actually in the room, as well as the augmentation of the cityscape they are working with for the purposes of urban planning. Placeholder objects are physically manipulated on the table, but replaced with the virtual models in the video result displayed to the users.
It's not hard to imagine that a sizable investment would be necessary for this system, given that each user requires a head-mounted display unit. The alternative is to use consumer devices with front mounted cameras like cell phones and tablet PC's, such as is seen in this image.
 (Image from http://studierstube.icg.tu-graz.ac.at/handheld_ar/smartphone.php)
(Image from http://studierstube.icg.tu-graz.ac.at/handheld_ar/smartphone.php)
It may not be as immersive as a system using headsets might be, but the potential for gaming is much more realistic for devices that everybody already owns. And that's where the seminar concludes: Dr. Roth believes that with an investment of several inexpensive tablet computers upgraded with inertial devices, some really interesting collaborative games could be developed. I'd be up for that!
It's not hard to imagine that a sizable investment would be necessary for this system, given that each user requires a head-mounted display unit. The alternative is to use consumer devices with front mounted cameras like cell phones and tablet PC's, such as is seen in this image.
(Image from http://studierstube.icg.tu-graz.ac.at/handheld_ar/smartphone.php)It may not be as immersive as a system using headsets might be, but the potential for gaming is much more realistic for devices that everybody already owns. And that's where the seminar concludes: Dr. Roth believes that with an investment of several inexpensive tablet computers upgraded with inertial devices, some really interesting collaborative games could be developed. I'd be up for that!
Thursday, January 10, 2008
Online Resources for CS Students
I recently received an email from a lady at the Virtual Hosting blog (not entirely sure why they have a blog, or why they blog about such strange things as I'm seeing on their front page right now, but anyway....). They posted an article called "50+ Killer Online Resources for Computer Science Students". She thought you, my readers, might be interested. I checked out a few links and it looks like there should be some good stuff there. Let me know if you liked it!
Wednesday, January 9, 2008
The "COMP 4804" Debate
There has been a bit of debate going on at our School of Computer Science for a while now. The big question is whether a fourth year algorithms course should be or shouldn't be included in particular streams of the Bachelor of Computer Science degree (for example, the game development stream). The argument is that the more applied areas of computer science have too much else to learn, and that these more difficult courses may be scaring students away.
Personally, I think it should always be required, since it is the stuff at the heart of computer science in the first place!
Before we go any further, let me share with you the calendar description for the course:
The last three points are what the course focussed on most when I took it (I believe some of the subject matter has been shuffled between the always mandatory COMP 3804 and this course). I honestly cannot imagine any computer science degree (which, it should be noted, is very different from a software engineering degree or a computer programming diploma) being complete without an understanding of these topics!
The pure-theory algorithms folk at school will naturally tend to push this course as mandatory, as it represents everything they do. But the professors who work in more applied subjects should care just as much! At the end of the day, everyone needs algorithms to accomplish their tasks. And nobody is immune to encountering problems that can be solved efficiently using approximations or randomized processes, or perhaps even problems that can't be solved efficiently at all!
Imagine the time that could be wasted on trying to solve a problem that ends up being NP-complete. If you don't know how to recognize it as such, you might hammer away at it until you realize you have too much data to crunch and not enough time to crunch it in. It's not that unlikely, no matter the domain!
Of course, if you do go to grad school without this knowledge, you will be at a huge disadvantage. I've attended only one computational geometry class so far this year, and already randomized algorithms were used to solve the very first example. Having taken COMP 4804 made all the difference in understanding what was going on right away rather than having to struggle to figure it out later on. The weirdest part is that COMP 4804 isn't even required to get into grad school, and since many computer science streams (including at our own school!) don't require it, there's a pretty good chance that you just won't have the knowledge when you start your graduate studies.
What do you think? Have you taken an advanced algorithms class and loved it? Or do you think it really isn't always all that useful? Share your thoughts as comments!
Personally, I think it should always be required, since it is the stuff at the heart of computer science in the first place!
Before we go any further, let me share with you the calendar description for the course:
COMP 4804 [0.5 credit]
Design and Analysis of Algorithms II
A second course on the design and analysis of algorithms. Topics include: advanced recurrence relations, algebraic complexity, advanced graph algorithms, amortized analysis, algorithms for NP-complete problems, randomized algorithms. Also offered at the graduate level, with additional or different requirements, as COMP 5703, for which additional credit is precluded.
Prerequisite: COMP 3804 or permission of the School.
Lectures three hours a week.
The last three points are what the course focussed on most when I took it (I believe some of the subject matter has been shuffled between the always mandatory COMP 3804 and this course). I honestly cannot imagine any computer science degree (which, it should be noted, is very different from a software engineering degree or a computer programming diploma) being complete without an understanding of these topics!
The pure-theory algorithms folk at school will naturally tend to push this course as mandatory, as it represents everything they do. But the professors who work in more applied subjects should care just as much! At the end of the day, everyone needs algorithms to accomplish their tasks. And nobody is immune to encountering problems that can be solved efficiently using approximations or randomized processes, or perhaps even problems that can't be solved efficiently at all!
Imagine the time that could be wasted on trying to solve a problem that ends up being NP-complete. If you don't know how to recognize it as such, you might hammer away at it until you realize you have too much data to crunch and not enough time to crunch it in. It's not that unlikely, no matter the domain!
Of course, if you do go to grad school without this knowledge, you will be at a huge disadvantage. I've attended only one computational geometry class so far this year, and already randomized algorithms were used to solve the very first example. Having taken COMP 4804 made all the difference in understanding what was going on right away rather than having to struggle to figure it out later on. The weirdest part is that COMP 4804 isn't even required to get into grad school, and since many computer science streams (including at our own school!) don't require it, there's a pretty good chance that you just won't have the knowledge when you start your graduate studies.
What do you think? Have you taken an advanced algorithms class and loved it? Or do you think it really isn't always all that useful? Share your thoughts as comments!
Friday, January 4, 2008
Portfolio Showcase
I think that every professional in our industry deserves a good portfolio. Far too often have I seen well-intentioned students grab a domain name and slap up a basic infrastructure with the text "more to come soon." I tend to check back because I am interested in what friends and colleagues are up to, but I rarely see anything new.
Granted, these people generally do a lot behind the scenes because this is what they are interested in. They like to set up content management systems or write their own code. I went the other route with my portfolio: I just used Dreamweaver to put something together fairly quickly. I don't even know if it is completely valid HTML or CSS. My friends would cringe at the thought! :)
I'm glad I decided to go this way, if for no other reason than the fact that it's been really easy to actually add the content. I have no desire or need to update the back end to the latest and greatest, so I can concentrate on what really counts to me. I love being able to add information about my latest school projects or cool graphics I've made.
Which brings me to the real point of this post: to showcase my portfolio! I am planning to change hosts and my new domain gailcarmichael.com will eventually point to the portfolio instead of redirecting to this blog, but until then, check me out at http://www.scs.carleton.ca/~gbanaszk/. Drop me a comment if you liked anything you saw, or better yet, tell me where to find your portfolio!
Granted, these people generally do a lot behind the scenes because this is what they are interested in. They like to set up content management systems or write their own code. I went the other route with my portfolio: I just used Dreamweaver to put something together fairly quickly. I don't even know if it is completely valid HTML or CSS. My friends would cringe at the thought! :)
I'm glad I decided to go this way, if for no other reason than the fact that it's been really easy to actually add the content. I have no desire or need to update the back end to the latest and greatest, so I can concentrate on what really counts to me. I love being able to add information about my latest school projects or cool graphics I've made.
Which brings me to the real point of this post: to showcase my portfolio! I am planning to change hosts and my new domain gailcarmichael.com will eventually point to the portfolio instead of redirecting to this blog, but until then, check me out at http://www.scs.carleton.ca/~gbanaszk/. Drop me a comment if you liked anything you saw, or better yet, tell me where to find your portfolio!
Thursday, January 3, 2008
Street Selection and Self-Organizing Maps
Maps have become an essential part of many of our lives, helping us to get from one place to another for centuries. With the widespread availability of relatively recent digital technologies, such as Google Maps, the need to display maps at different resolutions has never been greater.
Think of the kinds of features that are shown in this map of Canada:
View Larger Map
Not a lot is shown beyond a bit of water and some major political markings. When zooming into Ontario, bodies of water become more clear and major roads are now shown:
View Larger Map
Finally, much more detail, including local roads, is possible when looking at just the city of Ottawa:
View Larger Map
There is obviously some decision making happening behind the scenes in order to display the most important features for a particular level of zoom (or resolution, as it were).
Let's look specifically at road networks, ignoring the other features for this discussion. There are two levels of work to be done when determining what roads should be shown at a particular level of detail. This whole process is known as generalization, since we must decide what subset of all the available information will be shown.
The first step of generalization involves examining the model of the road network and using information about street connections, types, and so on to pick out the most important or relevant pieces to show.
Once we have the data that is to be visualized, the second step analyzes the geometric properties of the chosen roads and uses the results to simplify the graphical rendering of the roads. For example, a road with many small bends that can't be rendered onto the screen as such will be simplified to a straight line instead.
It is in the first step that self-organizing maps (or SOMs) can play a role. These maps are actually neural networks that are used to cluster and visualize data. To make a longish story short (and simplified), you create vectors with as many dimensions as you have numerical properties about each item you want to cluster. Using these numbers, the SOM sorts out the data so that items that are most alike end being "close" together. You might, for example, have a SOM that is represented by a two dimensional grid, and the input vectors will be organized into the cells based on their similarities.
In the case of selecting roads from a network, there are some obvious numerical values that can be used to describe each street for use in the SOM, such as length. There are, however, also some less obvious choices that seem to help categorize roads in a more useful way. A good list of attributes for each road is as follows:
For more information, please have a look at my final project for the GIS class I took in the fall semester. I implemented street selection using SOMs. The file includes my write-up of the project as well as the Java code used. Be sure to look at the README file if you plan to play with it as you will need to do a bit of work to set things up.
Think of the kinds of features that are shown in this map of Canada:
View Larger Map
Not a lot is shown beyond a bit of water and some major political markings. When zooming into Ontario, bodies of water become more clear and major roads are now shown:
View Larger Map
Finally, much more detail, including local roads, is possible when looking at just the city of Ottawa:
View Larger Map
There is obviously some decision making happening behind the scenes in order to display the most important features for a particular level of zoom (or resolution, as it were).
Let's look specifically at road networks, ignoring the other features for this discussion. There are two levels of work to be done when determining what roads should be shown at a particular level of detail. This whole process is known as generalization, since we must decide what subset of all the available information will be shown.
The first step of generalization involves examining the model of the road network and using information about street connections, types, and so on to pick out the most important or relevant pieces to show.
Once we have the data that is to be visualized, the second step analyzes the geometric properties of the chosen roads and uses the results to simplify the graphical rendering of the roads. For example, a road with many small bends that can't be rendered onto the screen as such will be simplified to a straight line instead.
It is in the first step that self-organizing maps (or SOMs) can play a role. These maps are actually neural networks that are used to cluster and visualize data. To make a longish story short (and simplified), you create vectors with as many dimensions as you have numerical properties about each item you want to cluster. Using these numbers, the SOM sorts out the data so that items that are most alike end being "close" together. You might, for example, have a SOM that is represented by a two dimensional grid, and the input vectors will be organized into the cells based on their similarities.
In the case of selecting roads from a network, there are some obvious numerical values that can be used to describe each street for use in the SOM, such as length. There are, however, also some less obvious choices that seem to help categorize roads in a more useful way. A good list of attributes for each road is as follows:
- Number of streets that intersect this one
- A measure of closeness between this road and all others around it, using shortest path distances
- A measure of betweenness, the proportion of shortest paths between all other roads that pass through this one
- Length and width (i.e. number of lanes)
- A numerical representation of the class of road (i.e. avenue, street, highway, freeway, etc)
- Speed limit
For more information, please have a look at my final project for the GIS class I took in the fall semester. I implemented street selection using SOMs. The file includes my write-up of the project as well as the Java code used. Be sure to look at the README file if you plan to play with it as you will need to do a bit of work to set things up.
Subscribe to:
Posts (Atom)